
For years, the world wanted “real” things in their products – like real milk, real cheese, real juice, and real bacon. But then the world changed – now people want more artificial things – artificial meat, artificial furs and, of course, artificial intelligence, also known as AI technology or simply AI. From virtual assistants like Apple’s Siri®, Amazon’s Alexa®, and Microsoft’s Cortana®, to the use of AI in home appliances to help consumers make the perfect dinner, to IBM’s Watson® to help develop new drugs, consumers and businesses alike seem to have an insatiable appetite for more products and services that have “AI Inside.” For businesses, the use of AI is rapidly becoming not just a competitive advantage, but a must have business process. For consumers, AI brings the hope of an easier and more comfortable life.
The growth of AI should come as no surprise. Science and technology have made AI products that perform activities that traditionally would be performed by humans using their own intelligence more accessible and affordable to the masses while simultaneously advancing the technology by leaps and bounds towards general purpose artificial intelligence systems that rival human intelligence itself. AI is most definitely not only here to stay, but will continue to be a larger and larger part of business operations.
Many businesses still believe, however, that contracting for the development or use of AI products and services should be the same as contracting for the development or use of traditional software products and services. After all, some AI products are built solely in software, although hardware-based architectures that accelerate many of the basic operations used in AI are becoming more common – why isn’t contracting for the development or use of AI products and services the same as contracting for any other types of software products and services? While we will save the complex answer for later discussion, the simple answer is that the characteristics and design methodology of AI technology is very different from that of conventional software and, as a result, the legal issues when contracting for AI goods and services are fundamentally different than the issues that arise when contracting for traditional software. A failure to contract for AI technology differently than contracting for conventional software often results in the parties (both vendor and user) attempting to make unreasonable demands and either over- or under- valuing the different types of data and the significant use of know-how by both parties necessary to develop AI goods and services. As a result, contract negotiations for AI often fail. In this series of articles we explore what those differences are, how and why they arise, and some ideas on how to tackle them.
Different Types of AI Technology
The terms “artificial intelligence” or “AI” are often used as generic terms for a type of technology referred to as “machine learning.” Machine learning is a technology that aims to “teach” a computer to do various tasks by finding particular rules in certain types of data and making inferences or predictions regarding other data based on those derived rules. This involves developing these rules inductively based on actual observed events (the data) instead of using the deductive approach commonly used for conventional software. Deep learning is a subcategory of machine learning that attempts to draw more accurate inferences through the use of a neural network. A neural network attempts to imitate the processing of a human brain through the use of many small processors with significant interconnection. Although this type of learning was traditionally implemented in graphic processors (GPU’s) due to the similar characteristics in GPUs of many processing units with high connectivity, more recently processors specialized for artificial intelligence have and are being developed.
Differences Between Conventional Software Development and the Development of AI Technologies
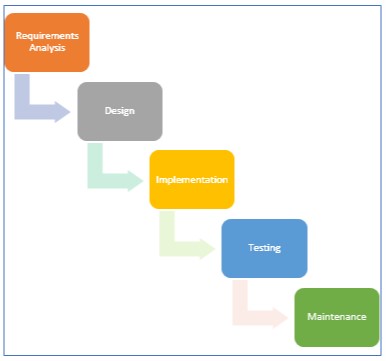
Since the beginning of computers, the development of conventional software has been through the use of a deductive process, usually through a “waterfall” development model. For a software developer, the task is relatively simple: first, the software specifications are defined in detail based on known rules (algorithms), and then the software is designed, implemented, tested and gradually refined until all of the desired functions have been implemented and the rules have been met. A typical conventional software development process is shown below. In general, going backwards in the flow is relatively rare other than some refinement to the design or implementation as a result of bugs discovered through testing.
However, the development of AI technology, and specifically machine learning, is based on a fundamentally different concept. Machine learning is a type of training for finding the particular rules given both input and output data (or events) and later making inferences and predictions regarding user data based on these derived rules. This is accomplished through the use of inductive development methods using actual observed input and output data, generally without any understanding of any rules or algorithms that resulted in the output given the input. The goals are analyzed, an initial AI architecture and initial parameters are tried, the results tested, and the process is repeated until the desired results are achieved. This often involves significant trial and error to understand the dataset and to adjust the structure and parameters of the AI processing elements until the desired results are achieved. A typical development process for AI technology is shown below.
|
Conventional Software Development
|
AI Technology Development Process
|

Challenges in Contracting for AI Technology
The inductive nature of machine learning creates certain problems for contracting that distinguish it from contracting for conventional software. However, there is one similarity – the mere use of AI that has already been developed has different concerns, and therefore demands a different contract approach, than AI being developed specifically for a party by the vendor. However, that is where the similarities generally stop and the intrinsic differences between conventional software and AI technology begin to create challenges in contracting. Some of the major challenges are as follows:
- The results from AI models may not be accurate all the time, but rather a certain small percentage of errors should be tolerated. Because AI technology derives rules based on training data with certain statistical properties and then tries to apply it to unknown data with potentially slightly different statistical properties, the output of AI technology occasionally may be incorrect. This is different than conventional software, where data that meets the rigorously defined parameters is expected to yield the correct result 100% of the time, and data outside those parameters are expected to be rejected. As a result, the specifications for an AI model are often measured in error rates.
- Challenges for the vendor to offer a performance guarantee in advance: Because the development of an AI technology depends so heavily on the training data set, it is difficult for a vendor to know at the time of contracting how the resulting AI technology will perform on the user’s data set when the parties execute the contract. If the statistical properties of the training data set and the user data are significantly different from one another, including if the training data doesn’t include statistically rare events, the AI model may ultimately fail once put in production.
- It is very difficult to verify an AI model: With conventional software, if the expected performance has not been achieved, the root cause can often be identified and remedied by repeated verification and modification of the software. On the other hand, the creation of AI technology is very difficult for humans to understand. As a result, when the AI does not perform as anticipated, it is difficult to determine if the root cause is the quality of the training data, if it is the structure or initial parameters of the neural network, or a traditional software or hardware bug that is causing the non-conformance.
- Unlike conventional software development, developing an AI model is inherently a process of trial and error: The parties to an agreement for AI technology should expect that the vendor will spend a significant amount of its resources (usually in the form of people) in processing or adjusting data to find the right model structure and parameters to achieve the results.
- The contents and performance of AI models depend heavily on the training data: Training of the AI, and ultimately the results it generates, is heavily dependent on the statistical qualities of the training data compared to the data when in use. It is generally very difficult, if not impossible, to eliminate all statistical biases from training datasets, and these training data sets often do not contain statistically rare events. Furthermore, the assumption is that the statistical properties used in the training data and the use data are substantially identical. As a result, incorrect or unanticipated results can occur if there is a difference in the statistical properties between the training data and the use data, especially when the use data contains rare events. This can also result in the AI model being unusable or require the vendor to develop different versions of the AI for different users.
- The value of know-how is particularly high when creating and using AI models: Although the development of conventional software also requires a certain amount of know-how, know-how tends to be even more important when developing AI technology. For example, the know-how associated creating training data and setting the initial parameters of AI is important on ensuring that the AI not only meets the requirements, but is statistically accurate such that it represents the user data and minimize errors. Even the statistical properties themselves of the training data may be the result of either the user’s or the vendor’s know-how after years of processing this data with traditional methods. Furthermore, because the creation of AI technology may require more trial and error, know-how in the form of what to try next may be particularly important to converge on an AI that meets the goals.
We will delve further into the contractual impacts of these challenges in later installments of this series.
Conclusion
Contracting for the development and use of AI technology must be different than contracting for the development and use of conventional software. This is largely a result of the inductive nature of AI technology development as contrasted to the deductive process generally used by conventional software. Furthermore, the quality of the AI model depends largely on the training data used – as the old saying goes, garbage in, garbage out. Users should be aware of these differences while contracting and be prepared to adjust their contracting practices away from the practices used when contracting for traditional software services to something … different. In our upcoming installments, we will describe the key components necessary for both the development and use of AI technology, the IP implications of each of these components from both the user’s and the vendor’s perspective, and describe contract approaches that can be deployed to reach a reasonable agreement between the parties.


